
VGG는 기본적인 CNN의 구조에 깊이를 증가시킨 형태이다. 논문 "Very Deep Convolutional Networks For Large-Scale Image Recognition" 의 제목과 개요에 나와있 듯 VGG는 신경망의 깊이를 깊게 하는데 중점을 두었다. 이러한 이유로 (3,3)의 작은 필터 사이즈를 주어 깊이를 최대로 늘리고자 했다. 필터가 작으면 피처맵의 사이즈가 조금씩 줄어드므로 합성곱 층과 풀링 층을 많이 쌓을 수 있기 때문이다. VGG팀은 최대 19개 까지 층을 늘리는 실험을 통해 층이 16개 이상일 때 성능이 좋다는 것을 발견하고 층이 16개와 19개인 VGG16, VGG19 모델을 만들었다.
아래의 표를 보면 D열이 VGG16, E열이 VGG19 이다. conv3-64는 (3,3) 사이즈의 필터 64개로 수행하는 합성곱 연산을 의미한다. 또한 필터의 개수는 해당 층의 깊이로 64개의 필터를 사용했다면 합성곱 층도 64개가 있다는 것을 뜻한다.
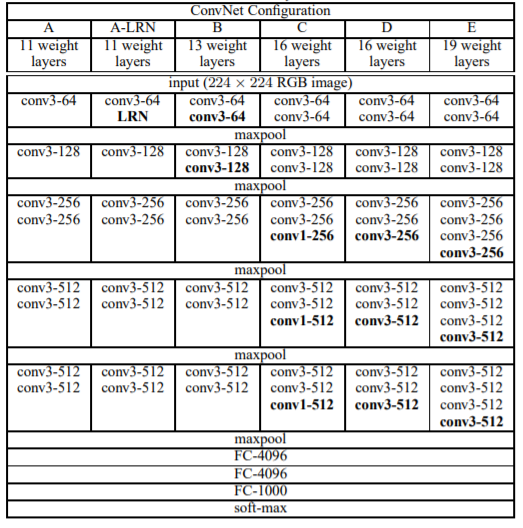
가장 성과가 좋았던 VGG16(D열)을 보자. 눈 여겨 볼 부분은 풀링을 하기 전과 후에 필터의 개수이다. 다시 말하면 해당 층의 깊이가 두배씩 깊어지고 있다. VGG는 풀 사이즈(2,2), 풀링 스트라이드는 2로 설정 했기 때문에 풀링 영역이 서로 겹치지 않는다. 결국 풀링을 하면 피처맵의 높이와 너비가 절반씩 줄어들게 된다. VGG는 최대 풀링 후에 필터 개수를 두배로 증가시켜 공간 차원의 크기는 감소되지만 깊이를 증가시켰다.
여기까지 VGG의 이론적인 부분을 살펴 보았다.
작성자 홍다혜 ghdek11@gmail.com / 이원재 ondslee0808@gmail.com
'【3】최근 CNN 응용 모델 이해하고 사용하기' 카테고리의 다른 글
| 이미지 분류하기 - 실습 (0) | 2020.02.10 |
|---|---|
| ResNet (이론) (0) | 2020.02.09 |
| GoogleNet (인셉션 모듈/평균 풀링/보조 분류기) (1) | 2020.02.08 |

